serverless framework 模块化部署
文章仅代表作者本人的认知,如有谬误,欢迎指正。
文章建议配合 @serverless/components 源码 食用
本文使用的示例代码 Forked from second-state/tencent-tensorflow-scf
这个仓库可以直接部署成一个 Serverless 的 AI 推理函数,很有意思
书接上回@serverless/components 代码简析
默认的模块化部署方案
官方有关于变量使用的文档和示例
app: ecommerce
component: express
name: rest-api
stage: prod
inputs:
name: ${stage}-${app}-${name} # 命名最终为 "prod-ecommerce-rest-api"
region: ${env:REGION} # 环境变量中指定的 REGION= 信息
vpcName: ${output:prod:my-app:vpc.name} # 获取其他组件中的输出信息
vpcName: ${output:${stage}:${app}:vpc.name} # 上述方式也可以组合使用
这种做法,让我想起了 vscode variables-reference
个人是很不喜欢这种写法的,尤其是 output 的值要在运行时才能拿到
不过这种方案的原理还是很值得了解的
How it works?
从 runAll 说起
// run.js
let instanceDir = process.cwd()
if (
!config.target &&
runningTemplate(instanceDir) &&
checkTemplateAppAndStage(instanceDir)
) {
return runAll(config, cli, command)
}
从上述代码可得,从 run 进入 runAll 模式要满足三个条件
- 执行
deploy且没有指定target选项 (指定自定义名称的 yml config) runningTemplate执行结果 返回值为 js 中true的表达式checkTemplateAppAndStage执行结果 也为true
runningTemplate做了什么?
首先,它会去在当前目录下找 possibleConfigurationFiles 即 :
serverless.[yml|yaml|json|js] 或 serverless.component.[yml|yaml|json]
只有 没有找到 的情况,这时候才会往 深一级 的目录 (排除startsWith('.')的文件夹,不是递归向下!),去找 serverless.[yml|yaml|json]文件
只有找到,且它的 component 字段有值,此时才返回 true
checkTemplateAppAndStage 做了什么?
抛开有一些和 runningTemplate 重叠的地方
它主要验证的,是 全部的 yml 文件配置中的 stage 和 app 字段
它验证所有配置文件中的 app 和 stage 是一样的,且不能存在空的情况
满足条件才会返回 true
满足了以上的三种情况,才能顺利的进入 runAll 模式
runAll.js 相比 run.js 部署的不同之处
主要体现在,它需要构建依赖关系和 output 的传递
// 核心不同点
const allComponents = await getAllComponents(templateYaml)
const allComponentsWithDependencies = setDependencies(allComponents)
const graph = createGraph(allComponentsWithDependencies, command)
const allComponentsWithOutputs = await executeGraph(
allComponentsWithDependencies,
command,
graph,
cli,
sdk,
credentials,
options
)
不同点大致就是上述代码:
使用 tencent-tensorflow-scf 用例进行部署
此时我们的 templateYaml 变量为:
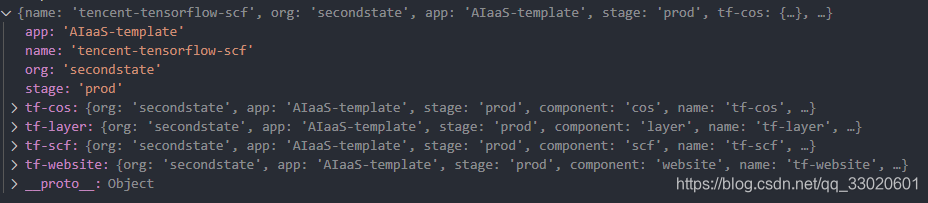
即部署四个,一个 cos, 一个 layer 一个 scf 和一个 website
getAllComponents
这个方法把 templateYaml 中的 components 过滤出来
setDependencies
这个方法才是所有处理 ${output:xxx} 变量的地方,目前只在 runAll 模式中可用,其他的变量如 ${env:xxx} ${stage} 等等 ,由 utils/resolveVariables 处理
那么它到底做了什么呢?
其实就一件事情,构建多个项目的依赖关系,然后赋值给 component.dependencies
例如:在这个示例中 tf-layer 使用了这样的配置 (部分):
inputs:
region: ${env:region}
src:
bucket: ${output:${stage}:${app}:tf-cos.bucket}
object: layer.zip
runtimes:
- CustomRuntime
此时通过依赖得知,它依赖 tf-cos 部署完成后的 bucket 变量
于是 tf-layer 依赖 tf-cos , 需要在它之后部署
createGraph & executeGraph
构建完依赖关系之后,就开始告诉机器,部署的优先级了
这里引入了一个数据结构,有向图 , 用来描述多个项目之间部署 (或者 remove) 的先后关系
部署的方向,根据依赖从前向后 deploy,最终到达每个顶点
而 remove 则是从后向前 remove
这个也很好理解,npm 包不也是这样的吗?
executeGraph 则是一个递归函数
每当一个项目部署完成,它都会把成功的结果,储存进 component 对象中,给下一个依赖它的项目使用
allComponents[instanceName].outputs = instance.outputs || {}
赋值后在图中,再把所有没有外边的节点给删除掉,并开始下一次的 executeGraph 的执行 ,直到不存在没有外边的节点
这样给我们做并发部署带来了很大的好处,总共递归的次数也就是图中最长路径的长度,即依赖的深度,从而提升了部署的效率
自定义模块化部署方案
serverless.yml 文件对我来说不够灵活
serverless.js 直接给 cli 使用又有诸多的问题
此时我们可以依据 ServerlessSDK + js-yaml 来达成我们模块化部署的需求
比如说,一个 yml 部署文件,我把它分为了:
base.jslayers.jsfunctionConf.jsapigatewayConf.jscustomDomains.js
这样带来的好处是,我们可以利用nodejs强大的编程能力,让部署变得灵活多变
比如动态的 src/exclude 选项,yml 文件往往要写很多,而且很死板,现在只需要
const rootList = fs.readdirSync('./')
const include = ['.nuxt', 'sls.js', 'dist', 'nuxt.config.js']
const exclude = rootList.reduce((acc, cur) => {
if (!include.includes(cur)) {
acc.push(cur)
}
return acc
}, [])
就能轻松的排除掉不需要的选项
另外使用 ServerlessSDK 可以直接使用 js 中的对象,这让我们可以直接生成 instanceYaml 对象
同时 ServerlessSDK 中的 sdk.getInstance sdk.deploy 方法,也可以用来取代 ${output}
当然不想使用 sdk, 还想使用 cli 部署也很容易, 使用 js-yaml dump 一下 js 对象即可使用命令行部署
以直接使用 js 中的对象,这让我们可以直接生成 instanceYaml 对象
同时 ServerlessSDK 中的 sdk.getInstance sdk.deploy 方法,也可以用来取代 ${output}
当然不想使用 sdk, 还想使用 cli 部署也很容易, 使用 js-yaml dump 一下 js 对象即可使用命令行部署